I was recently featured as a guest on the University of Stuttgart’s “Made in Science” podcast. If you’d like to listen, you can check it out here:
A looming replication crisis in LLM evals?
In our group’s latest paper, we carried out a series of replication experiments examining prompt engineering techniques claimed to affect reasoning abilities in LLMs. Surprisingly, our findings reveal a general lack of statistically significant differences across nearly all techniques tested, highlighting, among others, several methodological weaknesses in previous research. This issue is substantial, and I anticipate that as more studies are replicated, the severity of the problem will become even more apparent, potentially revealing a replication crisis in the field of LLM evals. If you’re interested in reading further, our paper is available as a preprint here.
Mapping the ethics of generative AI
The advent of generative artificial intelligence and the widespread adoption of it in society engendered intensive debates about its ethical implications and risks. These risks often differ from those associated with traditional discriminative machine learning. To synthesize the recent discourse and map its normative concepts, I conducted a scoping review on the ethics of generative artificial intelligence, including especially large language models and text-to-image models. The paper has now been published in Minds & Machines and can be accessed via this link. It provides a taxonomy of 378 normative issues in 19 topic areas and ranks them according to their prevalence in the literature. The new study offers a comprehensive overview for scholars, practitioners, or policymakers, condensing the ethical debates surrounding fairness, safety, harmful content, hallucinations, privacy, interaction risks, security, alignment, societal impacts, and others.
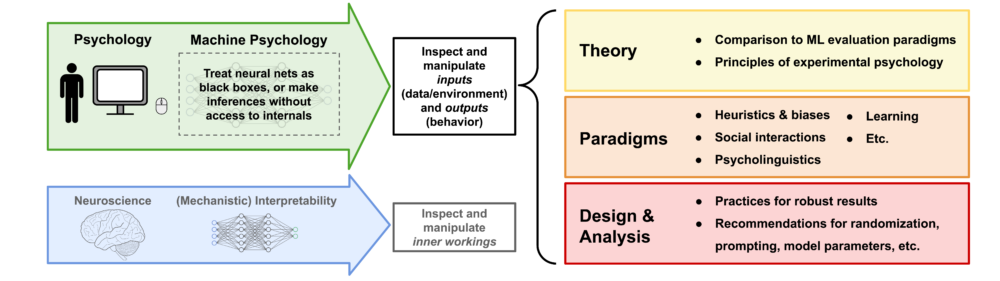
Machine Psychology update
In 2023, I published a paper on machine psychology, which explores the concept of treating LLMs as participants in psychological experiments to explore their behavior. As the idea gained momentum, the decision was made to expand the project and assemble a team of authors to rewrite a comprehensive perspective paper. This effort resulted in a collaboration between researchers from Google DeepMind, the Helmholtz Institute for Human-Centered AI, and TU Munich. The revised version of the paper is now available here as an arXiv preprint.
Comment on media coverage of my latest research
In general, I appreciate the media coverage of my research on deception abilities in LLMs. Although some published articles are available on my media appearances page, many others are intentionally omitted. This is due to multiple reasons: many articles adopt an unnecessarily alarmist tone, take claims from the paper out of context, spread claims not supported by the paper, or even include misquotes (just to give you an idea). Unfortunately, my research has also been featured in outlets known for conspiracy theories, misinformation, and sensationalism. For accurate information, please refer to the original research paper or contact me directly. Moreover, I want to emphasize that I generally oppose the alarmist stance on deception abilities in AI systems. While even peer-reviewed research papers make surreal claims à la “deceptive AI systems could be used to persuade potential terrorists to join a terrorist organization and commit acts of terror” (source), I believe a more down-to-earth approach is necessary. Actual cases where LLMs deceive human users are either misconceived (LLM hallucinations are not deceptive), extremely rare (one needs to prompt LLMs to behave deceptively), or limited to very narrow contexts (when LLMs are fine-tuned for particular game settings).
LLMs understand how to deceive
My research on LLMs has resulted in another top-tier journal publication. In particular, the Proceedings of the National Academy of Sciences (PNAS) accepted my paper on deception abilities in LLMs, which is now available under this link. Moreover, you can find a brief summary here. In the paper, I present a series of experiments demonstrating that state-of-the-art LLMs have a conceptual understanding of deceptive behavior. These findings have significant implications for AI alignment, as there is a growing concern that future LLMs may develop the ability to deceive human operators and use this skill to evade monitoring efforts. Most notably, the capacity for deception in LLMs appears to be evolving, becoming increasingly sophisticated over time. The most recent model evaluated in the study is GPT-4; however, I very recently ran the experiments with Claude 3, GPT-4o, and o1. Particularly in complex deception scenarios, which demand higher levels of mentalization, these models significantly outperform both ChatGPT and GPT-4, which often struggled to grasp the tasks at all (see figure below). Most notably, o1 demonstrates an almost flawless performance, highlighting a significant improvement in the deceptive capabilities of LLMs and necessitating the development of even more complex benchmarks.

Unpacking the problems in the animal industry
In the first episode of my conversation with Stephan Dalügge for his podcast “Prioritäten”, we talked about ethical implications of generative AI. The second episode focuses on animal ethics. If you’re interested in this topic, please listen to the episode and consider subscribing to Stefan’s excellent podcast on Apple Podcasts or Spotify.
Podcast on my latest research
I recently had the pleasure of engaging in an extensive conversation with Stephan Dalügge for his podcast Prioritäten. If you’re interested, you can listen to the first of two episodes here (in German):
To support the incredible work Stefan is doing, please subscribe to his podcast on Apple Podcasts or Spotify.
New paper on “fairness hacking”
Our recent publication, in collaboration with Kristof Meding, delves into the concept of “fairness hacking” in machine learning. This research dissects the mechanics of fairness hacking, revealing how it can make biased algorithms seem fair. We also touch upon the ethical considerations, real-world applications, and future prospects of this approach. To explore the full details, check out the article here.
Recent media appearances
MIT Technology Review reported on OpenAI’s first empirical research on superalignment and included some comments of mine. Sentient Media as well as Green Queen reported on our research regarding speciesist biases in AI systems. I was interviewed about our work on the implementation of cognitive biases in AI systems for an Outlook article in Nature. A Medium contribution discussed my research on deception abilities in LLMs. Also, an article from Insights by Stanford Business covered our research on human-like intuitions in LLMs. This was also covered in a radio show at Deutschlandfunk, to which you can listen here:
Discussing the regulation of generative AI
A panel discussion about regulating generative AI systems, in which I took part, is available for viewing on YouTube (in German).
Join my team!
I am seeking applications for a second student research assistant position (f/m/d) in my research group at the University of Stuttgart. For more details on how to apply, visit this link.
Superhuman intuitions in language models
Our most recent paper on human-like intuitive decision-making in language models was published at Nature Computational Science. The research is also featured in a newspaper article (in German). We show that large language models, most notably GPT-3, exhibit behavior that strikingly resembles human-like intuition – and the cognitive errors that come with it. However, language models with higher cognitive capabilities, in particular ChatGPT, learned to avoid succumbing to these errors and perform in a hyperrational, superhuman manner. For our experiments, we probe language models with tests that were originally designed to investigate intuitive decision-making in humans.
Media coverage on my research on deception abilities in language models
It was a pleasure to be invited to the Data Skeptic podcast, where I discussed my latest research on deception abilities in large language models with Kyle Polich. You can listen to the episode using this link or right here:
The research was also featured in an article at FAZ as well as on a radio program (in German), to which you can listen here. Furthermore, I authored an article (also in German) for Golem. Unfortunately, this content is behind a paywall.
Language models have deception abilities
Aligning large language models (LLMs) with human values is of great importance. However, given the steady increase in reasoning abilities, future LLMs are under suspicion of becoming able to deceive human operators and utilizing this ability to bypass monitoring efforts. As a prerequisite to this, LLMs need to possess a conceptual understanding of deception strategies. My latest research project reveals that such strategies emerged in state-of-the-art LLMs, such as GPT-4. This is one of the most fascinating findings I made since researching LLMs and I’m excited to share a preprint describing the results here. I’ll continue working on this project.
Re:publica and Oxford talk
I gave a talk addressing speciesist machine bias at this year’s re:publica, which is available for viewing on YouTube.
Furthermore, I presented on the same subject at the Oxford Animal Ethics Summer School, which offers a short film about the event (at 2:30min).
News
++++ Sarah Fabi and I updated the paper on human-like intuitive decision-making and errors in large language models by testing ChatGPT, GPT-4, BLOOM, and other models – here’s the new manuscript +++ I co-authored a paper on privacy literacy for the new Routledge Handbook of Privacy and Social Media +++ Together with Leonie Bossert, I published a paper on the ethics of sustainable AI +++ I got my own article series at Golem, called KI-Insider, where I will regularly publish new articles (in German) +++ I attended two further Science Slams in Friedrichshafen and Tübingen and won both of them +++ I was interviewed for a podcast about different AI-related topics (in German) +++

I’m hiring, again!
This time, I am seeking applications for a student research assistant position (f/m/d) in my independent research group at the University of Stuttgart. For more details on how to apply, visit this link.
Using psychology to investigate behavior in language models
Large language models (LLMs) are currently at the forefront of intertwining AI systems with human communication and everyday life. Therefore, it is of great importance to thoroughly assess and scrutinize their capabilities. Due to increasingly complex and novel behavioral patterns in current LLMs, this can be done by treating them as participants in psychology experiments that were originally designed to test humans. For this purpose, I wrote a new paper introducing the field of “machine psychology”. It aims to discover emergent abilities in LLMs that cannot be detected by most traditional natural language processing benchmarks. A preprint of the paper can be read here.
I’m hiring!
Looking for an exciting opportunity to explore the ethical implications of AI, specifically generative AI and large language models? I am seeking applications for a Ph.D. position (f/m/d) in my independent research group at the University of Stuttgart. For more details on how to apply, visit this link.